Многоагентный AI наделяет каждого члена команды LLM-агентом, который говорит, реагирует и принимает решения в выбранном вами сценарии. На выходе: chemistry-оценка, зоны конфликта и поимённые вердикты, обоснованные цитатами.
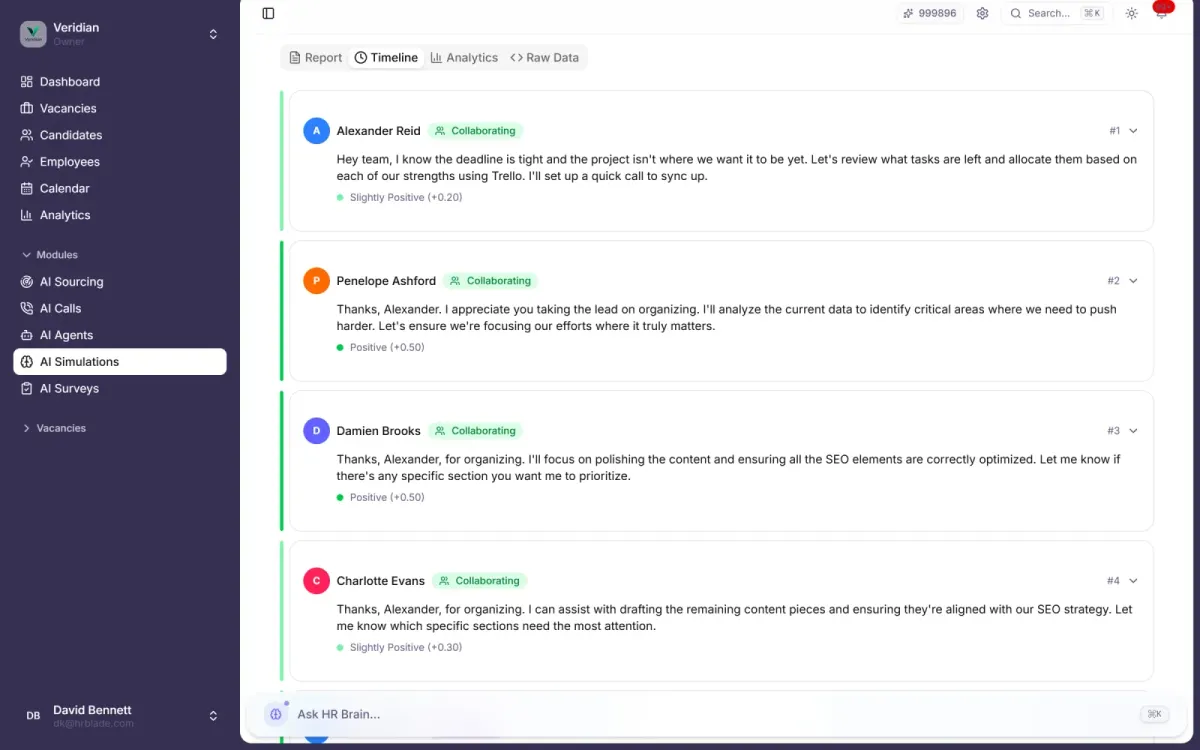
Это не чат-бот. Каждый участник становится character-агентом со своим реальным Big Five-профилем, стилем коммуникации, сильными сторонами и мотивацией. Поместите их в сценарий — командный конфликт, дедлайн под давлением, 90-дневный онбординг — и наблюдайте, как разворачивается динамика ход за ходом. После этого HRBlade анализирует диалог и говорит, что произошло бы на самом деле.
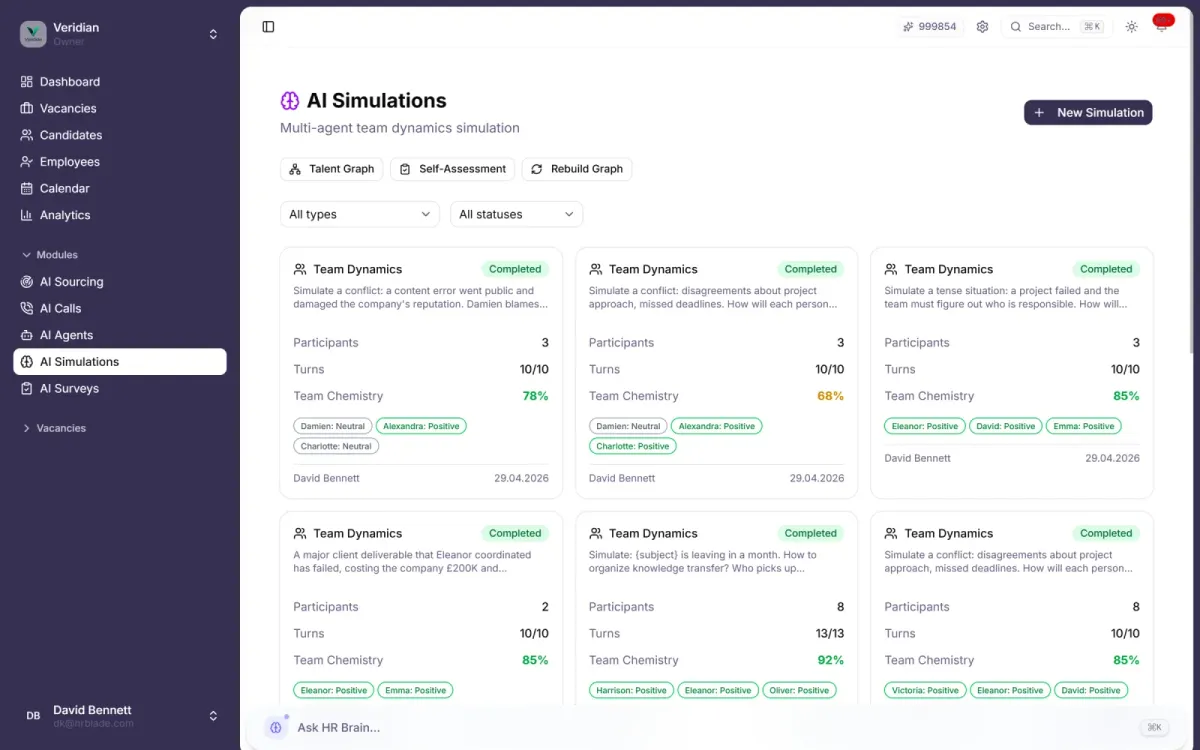
Впишется ли этот кандидат? Поместите его в действующую команду и наблюдайте, как формируется химия, трение и сотрудничество. Получите chemistry-оценку 0–100 с разбивкой по коммуникации, доверию, разрешению конфликтов и инновационности.
Шесть контрольных точек: с Дня 1 до Месяца 3. Видите траекторию интеграции, прогноз retention и ранние сигналы, которые обычно всплывают только после offer-letter regret.
Запустите ту же команду с кандидатом и без него. Дельта показывает реальный эффект на боевой дух, продуктивность, конфликтность и инновационность — измеримо, не на ощупь.
Стресс-тест реорга, урезания бюджета, слияния, ухода ключевого сотрудника. Опишите ситуацию своими словами — симуляция запустится и выдаст отчёт.
Каждая рекомендация цитирует ходы диалога, из которых она следует. Strong Hire / Hire / Cautious / Pass — с конкретными моментами, приведшими к выводу.
Агенты заполняются реальными Big Five-чертами, стилем коммуникации и био каждого человека — взятыми из транскриптов интервью, AI Surveys и ассессментов. Никаких generic-персон.
Укажите, кого оцениваем и в какую команду он входит. Профили автоматически подгружаются из записей кандидатов или сотрудников.
Совместимость команды, онбординг, leadership A/B — или опишите свою ситуацию обычным языком.
Около 15 ходов диалога и решений в роли. Каждый агент читает историю переписки и отвечает в своём голосе — с тональностью, действием и внутренними мыслями.
Поимённые рекомендации с цитатами-доказательствами, зоны конфликта с уровнем серьёзности, разбивка chemistry команды и нарративный отчёт на 4–6 абзацев.
Источник: Спецификация HRBlade SimulationEngine
Источник: Спецификация HRBlade SimulationEngine
Источник: Продукт HRBlade
Перед выдачей оффера прогоните кандидата против трёх ваших топ-исполнителей. Если chemistry < 60 и зоны конфликта высоки — вы только что сэкономили год дисфункции в команде.
Будет ли этот инженер хорошим EM? Запустите Leadership A/B симуляцию. Дельта по морали и инновационности команды — и есть ваш ответ.
Запустите 90-дневную симуляцию в День 1. Если траектория проседает на Неделе 2 — у вас есть время скорректировать курс до окончания испытательного.
Сливаете две команды? Перерисовываете линии подчинения? Запустите Custom-симуляцию и увидите, кто столкнётся, кто станет мостом, кто окажется изолированным.
Он опирается на реальный психометрический профиль каждого человека, его стиль коммуникации и заявленные мотивации — взятые из AI Surveys, транскриптов интервью и ассессментов. Диалог — не транскрипт того, что они скажут, а высоко-достоверная модель того, как они склонны реагировать. Воспринимайте вердикты как структурированное второе мнение, не как полиграф.
Раннее обнаружение риска ухода, выгорания и тихих конфликтов — с цитатами-доказательствами из открытых ответов.
Ваша база талантов — это граф, а не список. Найдите скрытые связи, пробелы в навыках и пути внутренней мобильности.
Учится на вашей истории найма. Корреляция ИИ-скоринга с performance через 6 месяцев: r = 0,74.