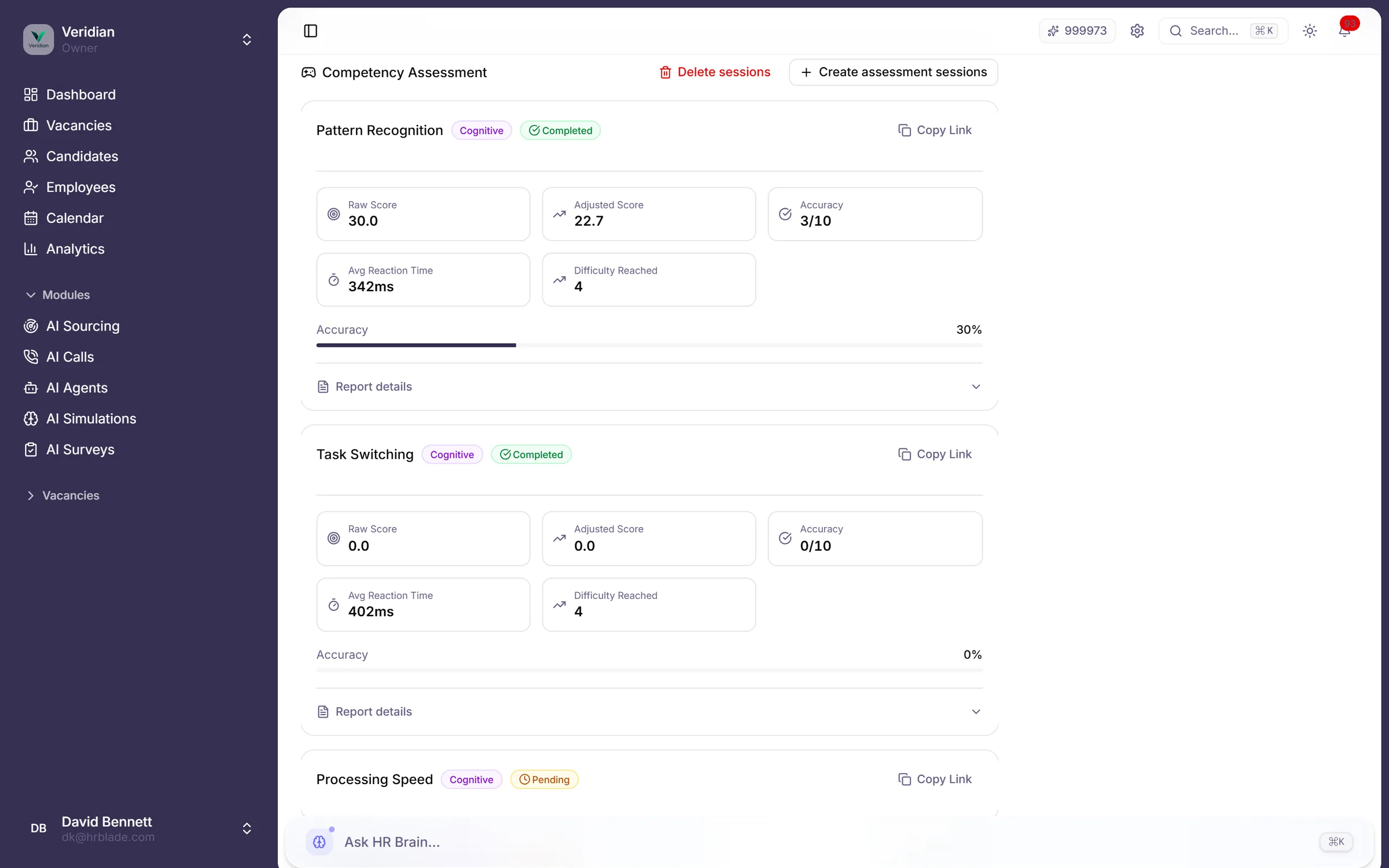
Computer Adaptive Testing (CAT) по 9 типам когнитивных игр: распознавание паттернов, рабочая память, переключение задач, скорость обработки, пространственное мышление, приоритизация, этические дилеммы, внимание к деталям, numerical reasoning. 95+ калиброванных задач. Сложность подстраивается на каждом ответе.
Классические психометрические тесты длятся 60+ минут и заставляют сильных кандидатов уходить. 9 адаптивных игр HRBlade проходят за 10 минут — сложность растёт при правильных ответах и падает при ошибках, поэтому вы получаете точный перцентиль за долю времени.
Распознавание паттернов, рабочая память, переключение задач, скорость обработки, пространственное мышление, приоритизация, этические дилеммы, внимание к деталям, numerical reasoning.
Каждый правильный ответ поднимает band сложности; каждый неправильный опускает. Модель быстро сходится к настоящему уровню кандидата — никаких 60-вопросных тестов.
Item-bank, валидированный против психометрических норм с item response theory (IRT). Параметры сложности перекалибруются ежеквартально по мере роста pool.
Кандидаты ранжируются на глобальной когорте 100k+ участников, сегментированной по семействам ролей. Скоринг найма имеет смысл в контексте, не как сырое число.
Детекция переключения вкладок, алерты по аномалиям времени на задачу, fingerprinting IP/устройства, опциональный webcam-проктор. Читеры идут в очередь review.
Вся батарея за ~10 минут vs 45–60 у классических тестов. Drop-off падает с ~30% до меньше 8% в наших pilot-данных.
Engineering: распознавание паттернов + рабочая память + скорость; sales: приоритизация + этические дилеммы + внимание к деталям. Настраивается per-requisition.
Mobile-friendly UI с инструкциями. Сложность сама подстраивается. ИИ трекает не только корректность, но и время реакции, паттерны retry и сигналы уверенности.
Страница результатов: перцентиль vs когорта, 5 скорингов компетенций, рекомендация pass/fail и follow-up probes для слабых зон.
Источник: Спецификация продукта HRBlade, 2025
Источник: Внутренний бенчмарк по 12k кандидатов, 2025
Источник: A/B-бенчмарк от клиентов, 2025
Customer support, ретейл, продажи — когда сигналов из CV мало, когнитивные ассессменты — самый сильный предиктор performance. Запускайте на 100% аппликантов.
Распознавание паттернов + рабочая память + пространственное мышление вместе с code take-home. Когнитивные скоринги коррелируют с pass-rate code review на r = 0,62.
Этические дилеммы + приоритизация + скорость предсказывают managerial-промоушены в 6-месячной follow-up когорте с точностью 83%.
Задачи спроектированы culture- и language-нейтральными (без идиом, без культурно-специфичных отсылок). Бенчмаркаем adverse impact по защищённым группам ежегодно с третьей стороной — I/O психологом; результаты публикуются по запросу.
Многоагентный AI моделирует реальную динамику команды — до найма, повышения или реорганизации.
Учится на вашей истории найма. Корреляция ИИ-скоринга с performance через 6 месяцев: r = 0,74.
Асинхронные и live. Автотранскрипция, скоринг по 5 компетенциям, многослойный anti-cheat.